
How I generate writing based on waitbutwhy — Explain Faiss
Explain similarity search in a simple way

I’m here to introduce some technical details on how I generate Tim Urban’s style of writing through waitbutwhy. This post is about how to search for the most similar context in waitbutwhy as a baseline to generate new writings from AI.
Let me give you an example.
Human: Can you generate writing about soy sauce in Tim Urban’s style?
AI: Okay, let me search through all of his posts to find the most similar sentences to start with before generating the soy sauce post. This is what I find.
fatty tuna on the right (all from the same fish). Interestingly, in the doc, Jiro says that the fattier pieces are simple and predictable and though most people like them the most, it’s actually the lean tuna where the subtle sophisticated flavor specific to that particular tuna comes out.
Tuna? Not bad. It is related to soy sauce. This message is cited from Tim Urban’s Japan, and How I Failed to Figure it Out.
How does AI do it? It’s using a similarity search called Faiss. Let me quickly explain to you.
What is Faiss?
Faiss (Facebook AI Similarity Search) is a method for similarity search. With Faiss, you can search for the most similar content that Tim has written related to your new topic. To put it technically: Given a set of vectors, we can index them using Faiss. Then, using another vector (the query vector), we can search for the most similar vectors within the index.
Let me explain it in simple terms.
Before using Faiss for your search, you will need to convert all the waitbutwhy writing into vectors so the computer can understand it. Next, you will ask a sample question: Can you generate writing about soy sauce in Tim Urban’s style?
Faiss will then search for the most similar context from waitbutwhy based on your query. How does Faiss do it? There are three popular ways, IndexFlatL2, Partitioning The Index, and Quantization.
Check everything — IndexFlatL2
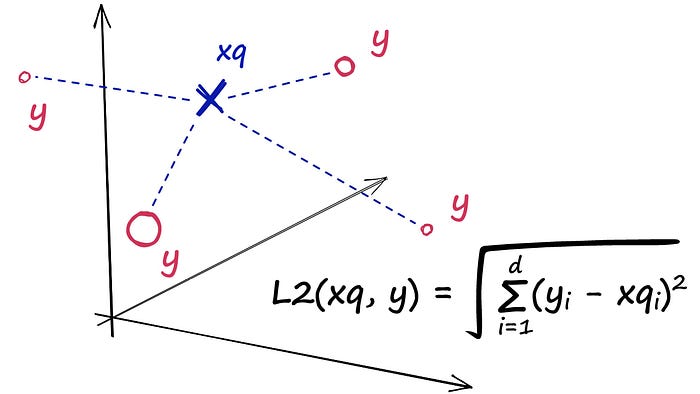
IndexFlatL2 is basically checking the distance between your query with all other vectors, meaning that you are checking “writing about soy sauce” with all the sentences in waitbutwhy. Since you are checking everything, the result is the most accurate, and simple, but slow.
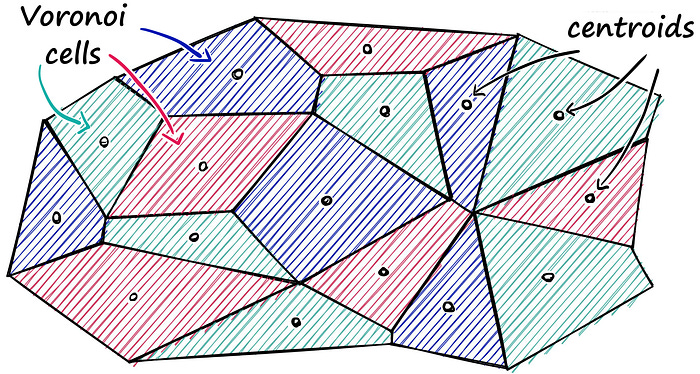
Check the neighbors only — Partitioning The Index
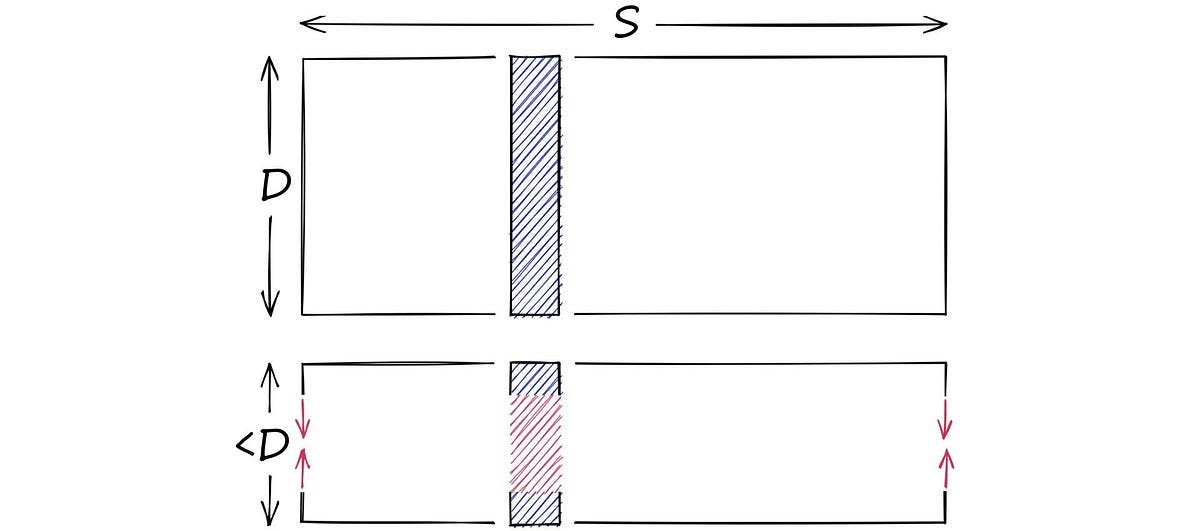
Voronoi cells are a magical geometric concept that can partition a space into regions based on proximity. Each region, known as a Voronoi cell, corresponds to a specific point and consists of all locations in the space that are closer to that point than to any other.
This means that we don’t need to search everything in waitbutwhy anymore, we just need to search the content in that specific cells using IndexFlatL2.
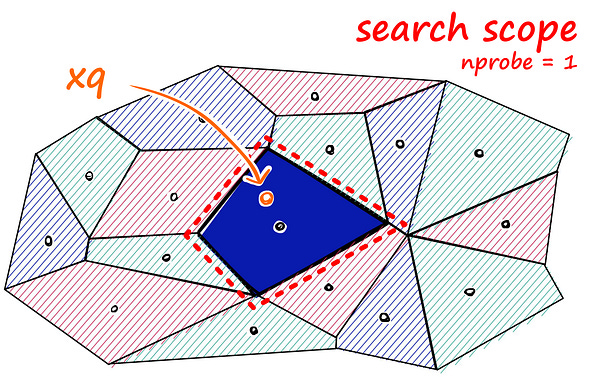
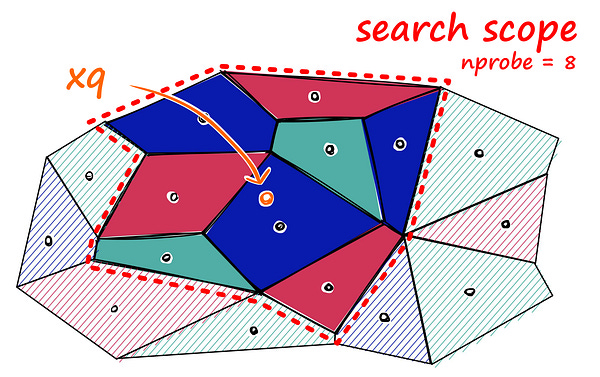
Since we reduce our search space, the output result will be an approximate answer. But if you think one cell isn’t enough, we can still expand the scope, finding other neighbors around that cell.
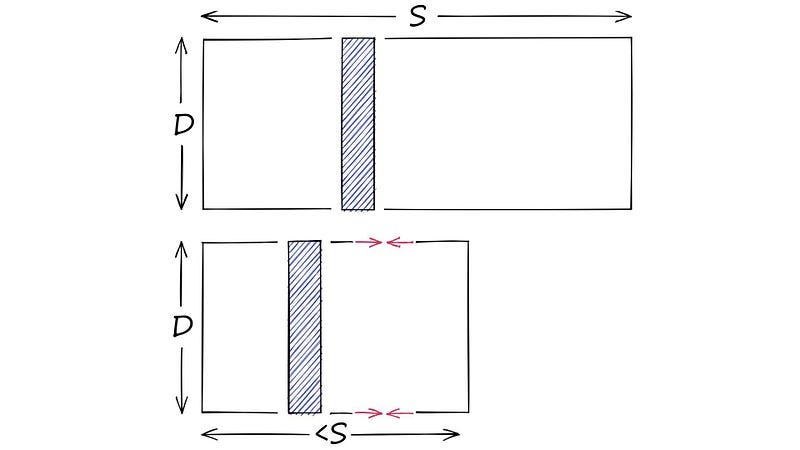
Grouping similar texts — Quantization
Faiss comes with the ability to compress vectors using Product Quantization (PQ). One way to do this is by clustering the vectors, which replace all possible vectors with a smaller set of discrete and symbolic centroids. This is similar to grouping similar texts in waitbutwhy to simplify the search.
If you understand dimensionality reduction, they are not the same! These two images explain the difference between them.
To understand the steps of quantization, you can use cooking as an analogy.
Taking a big, high-dimensional vector: You are cooking a complicated dish.
Splitting it into equally sized chunks — our subvectors: You try to break down all the ingredients of that dish.
Assigning each of these subvectors to its nearest centroid (also called reproduction/reconstruction values): You group similar ingredients together like the “Citrus Category” which includes lemons, oranges, and grapefruits. Another category could be a “Sauce Category” encompassing hot sauce, fish sauce, and barbecue sauce.
Replacing these centroid values with unique IDs — each ID represents a centroid: They are the Citrus and Sauce categories!
Therefore, when you search for soy sauce, you only need to search for things in the Sauce category! In short, Partitioning the Index is about dividing the index data into smaller subsets or partitions based on certain criteria. while quantization is about simplifying or reducing the number of options in a representation.
In my project, I’m using Langchain which uses the IndexFlatL2 method. After I fed AI the waitbutwhy search result, AI generate the soy sauce writing:
So, you know how there’s this thing called soy sauce? Yeah, that dark, salty, and oh-so-flavorful liquid that can make any dish go from meh to mouth-watering in just a splash. Well, let me tell you, soy sauce is like the ultimate wingman for your taste buds. Picture this: you’re sitting at a sushi joint, ready to indulge in a plate of mouthwatering rolls. And guess what? Right there, on the table, is that little bottle of magic called soy sauce. You grab it, give it a quick shake, and pour it over your sushi like a boss. Now, here’s a fun fact for you: did you know that in some high-end sushi joints, they request “no soy” for certain pieces? Yeah, they’re like, “Don’t you dare pour soy sauce on this bite of perfection, you foreign fool.” And you know what? They have a point. Because sometimes, the true flavors of a dish shine brightest without the soy sauce. But hey, no judgement here. Pour that soy sauce with reckless abandon if that’s what tickles your fancy.
Do you think this AI-generated writing is similar to Tim’s writing? You judge!
This is the 30th post from my 30-day writing challenges. I was inspired by Tung Nguyen, a friend who is a famous blogger. He overcame the fear of creation through mass-producing blogs and eventually found his own niche audiences.
Citation for knowledge and images: