

Introduction
I have been working on an AI learning company for two months that provides interesting knowledge and images whenever you have questions in your mind. For example, if you want to ask about 3D printing, the AI can generate information on that topic. This is one example that AI generates.
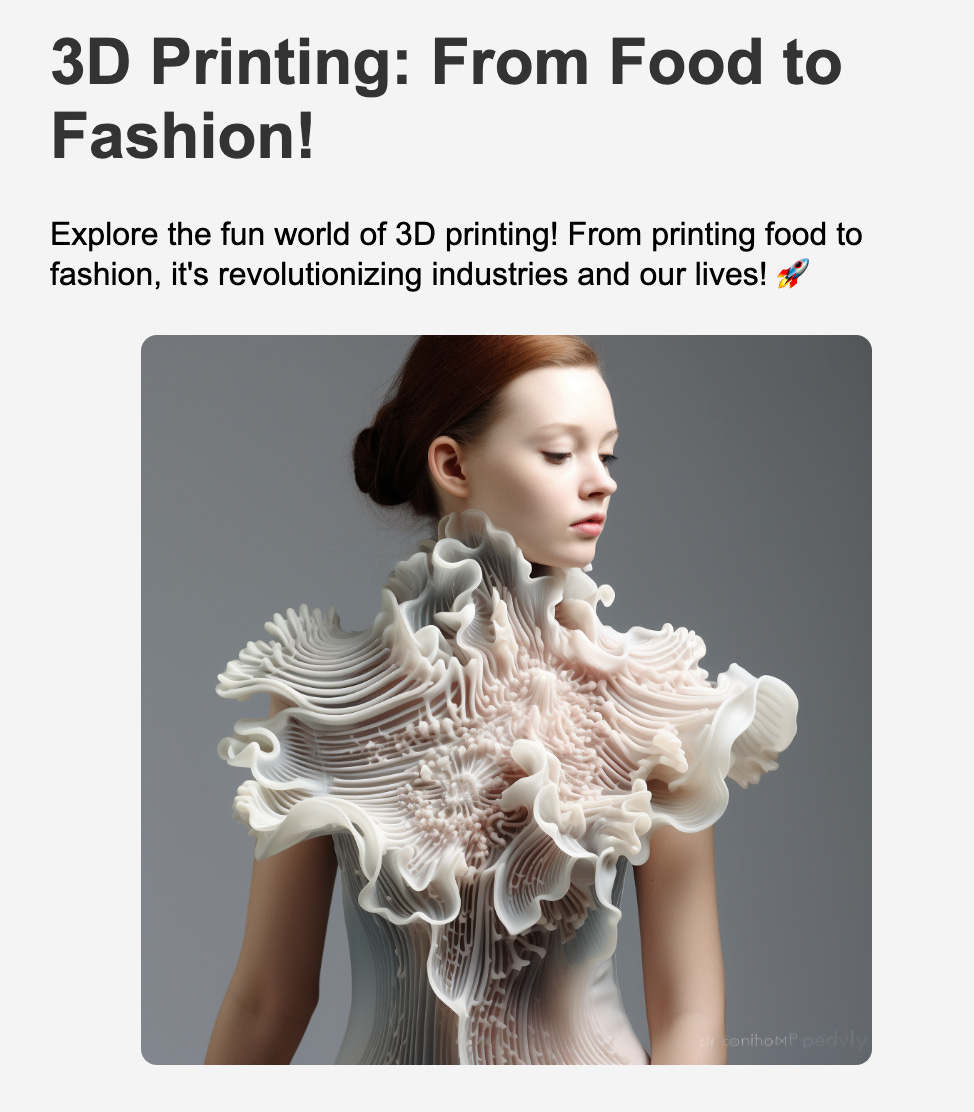

As an LLM Engineer, a significant portion of my work involves ensuring the quality of content and images. I evaluate whether the content provides meaningful information or is just a collection of meaningless words. I also check whether the images are relevant to the content. If you work on AI-generated images, you are likely familiar with the issues that AI faces. For example, people may appear distorted in the images, and the AI may generate lots of meaningless text.
Here are some of the things I have learned in my first two months on the job.
Simple instruction for LLM is usually better.
Before I joined, the old pipeline our company used had one prompt and asked AI to fit in 100 requirements. They asked AI to provide something interesting, be fun and engaging, avoid filler words, and not do certain things. They also asked AI to format some texts in style A, some in style B, and some in style C, D, E, F, G. When they asked AI to do so many things, AI became overwhelmed and the results were very poor.
However, if we understand that LLM/transformer is a series of predictions for the next word with some emphasis window (self-attention mechanism), we probably want to make sure AI can understand the one important goal and bias toward it rather than trying to achieve many goals at the same time. That’s why it’s usually better to do a chain if we have multiple objectives, but the trade-off will be latency. That’s why based on my experience the simpler the instruction, the better the performance.
Note: In addition, we also want to be aware of the initial dataset that it was trained on. Is our questioning format the same as the format that it was trained on? We should align our format with those.
Only Problems That Form a Pattern Are Worth Solving.
However, team members without a technical background may not understand it, and I often receive complaints such as “This image is off” or “That content is horrible”.
To be fair, I can make sure to resolve one specific content they complain about by specifying instructions. But is it worth the cost of the other 100 pieces of content that are good? So whenever my team members complain about content or image quality, the first question I ask myself is usually:
Is it a corner case or a pattern?
If it isn’t a pattern, it probably isn’t worth solving.
Keen Observations are the Key to Resolving LLM Problems.
One week, our founder kept saying “Our image AI is on LSD!” because the images the AI-generated were often rainbow-colored, crystal-like complicated patterns, and had a mix of colors in the background. To them, it seemed like the world was collapsing because everything was scary. However, when I looked into the problem, I noticed that all the “LSD images” were because the content was introducing abstract topics such as social justice and equality. The AI didn’t know how to draw them, so they got creative.
After giving them prompts to generate more concrete objects, many images became significantly better.
“Great work, Esther!” My founder beamed. Little did he know that it only took me less than an hour to figure this out and resolve this issue that seemed to be so large in scale. When this technology is so new, a scientific mindset such as observation, hypothesis, and experimentation is my toolkit.
The trade-off in LLM
The Trade-off Between Depth and Length, and Tone
When my team expressed dissatisfaction with the content quality, saying things such as “the texts are too long,” “the content isn’t informative,” and “there is no personality in the text,” I provided several examples to illustrate how content often represents a trade-off between various factors.
The following are three examples of writing about Giffen Goods:
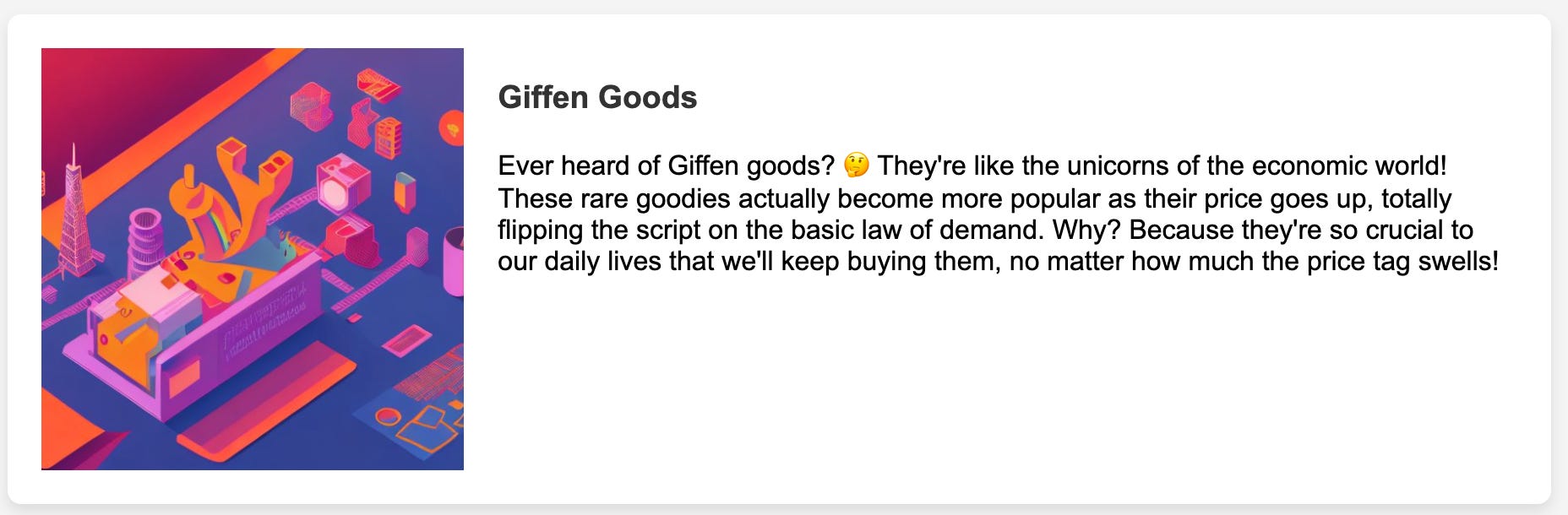

As you can see,
Example 1 (Top): It has the most personality with an analogy to assist understanding. However, it has filler words, such as “Ever heard of Giffen goods?”
Example 2 (Middle): It still has some personality, and we successfully solved the problem of long texts. However, it suffers from some information loss.
Example 3 (Bottom): It has adequate information with an acceptable length, but now it looks like a boring textbook!
Beyond the trade-off of tone, length, and depth, a trade-off exists in all prompt engineering practices because when AI is biased toward achieving one goal, some other things get sacrificed. If we are not trying to train a better, bigger model but building an LLM application in production, we have to lean toward whatever is more aligned with our business goals and user needs.
The Trade-Off Between Latency and Content Quality
Users feel frustrated if they have to wait more than a minute for the output after inputting their request. While it’s possible to train small models on specific tasks to reduce latency, these models will perform poorly if we ask them to handle tasks outside their domain. As I develop a general-purpose learning app, I’m hesitant to sacrifice content quality for speed.
You might ask, “Why not just stream the output?” However, the challenge I face in production involves a complicated chain of data validation and product requirements before sending the content to the users. Would users prefer waiting a minute to see the complete content or waiting 10 seconds to flip through every page?
I believe that as more AI tools with easy usage become available in the future, we might find a way to resolve this trade-off. For now, I’m trying to balance the competing demands of latency and content quality.
Prompt Engineering is Underestimated.
Most engineers think that prompt engineering isn’t “real” engineering. My engineer friend likes to say, “It’s just a GPT API wrapper.” But if I can soon create better prompts to replace coding, is it still stupid?
As an engineer, I used to find prompt engineering to be unimportant. Training on clusters and thinking about gradients seemed to be much cooler. However, from a business perspective, prompt engineering usually provides the biggest value at the lowest cost for content generation tasks.
Although there are already many prompt engineering cookbooks, it still requires lots of imagination and creativity to get the most out of this new technology. I hypothesize that we haven’t exhausted the potential of prompt engineering due to the indeterminate output and lack of an assistive evaluation tool in LLM.
Building a content evaluation tool is difficult, even through fine-tuning AI evaluation. But systematic exploration of prompts already exists. My friend built Baserun for prompt testing and evaluating output, which is a first step towards systemizing this process.
Using Temperature as a Simple Design for Fall-Back Systems and Data Validation.
Currently, I use datatype checking to ensure that AI output is in the desired format. When it is not, I change the temperature to create variation and ask the AI to rerun. Langchain has an output parser tool for this purpose, but from my testing, their parser tool is not reliable, so I prefer to test on my own. Guardrail AI also has its own testing system, but while its design philosophy makes sense, the implementation is not intuitive, so I have not yet tried it.
Overall, rerunning is not ideal as it takes up more time. Additionally, data validation requires returning the entire AI output, which takes away the advantage of streaming. I would love to learn more about solutions for these aspects.
It’s super important to communicate the possibilities and limitations of LLM to your team.
In a team where most people don’t really know how LLM works, I gradually realized the importance of communicating the information gap. There are two main points that I keep communicating with my team:
Improvement isn’t linear, and my timeline differs from people’s expectations. My team seems to expect that the content will gradually improve day by day, but that’s a misunderstanding. I will need to build the infrastructure, validate the output, examine the latency, and experiment with different prompts and combinations of chains. But when I’m done with it, it will be a totally new version of output. Conversely, sometimes I can simply change the prompt in 5 minutes and fix some significant problems. My team might think I worked a lot to make this great progress, but it’s actually much simpler and quicker than they expected. Overall, the timeline I’m working on isn’t as linear as they think, so I need to provide them with more context on how AI works.
Generating content that balances our expectations (users’ needs in the future) matters more than satisfying everyone. In the “Trade-Offs Between One, Depth, and Length” section, I showed that people want content that is fun, with in-depth knowledge, and a comfortable length. However, I’ve started to communicate with them that there is a trade-off or balance we can achieve rather than satisfying everyone’s needs. I’m not discounting that with better models, we might find a happy balance. But it requires clear and measurable “amazing content” that needs much more user feedback data and iterations, rather than personal judgments. As an LLM engineer, I’m learning how to communicate with my team to implement future practices that allow for scaling and acknowledge current constraints and trade-offs.
Here is what I have learned so far, but every day I still feel like I don’t know shit about LLM. Please let me know if you have any additional ideas for improving LLM engineering practices!